Influence at Scale: Distributed Computation of Complex Contagion in Networks
-
Brendan Lucier, Joel Oren, Yaron Singer
-
KDD 2015
概要
-
ICモデルでのσの推定
-
新しい標本
-
MapReduceで分散も
-
グラフはでかいので分割,クエリを打っていく
-
Q. どのくらいのクエリが必要?
-
実験してMCより良い
予備知識
-
link-serverモデル
-
[Bar-Yossef, Mashiach, CIKM'08], [Bressan, Peserico, Pretto, '14]
-
クエリ: v
-
レスポンス: N-(v)とN+(v)と辺確率
標本手法
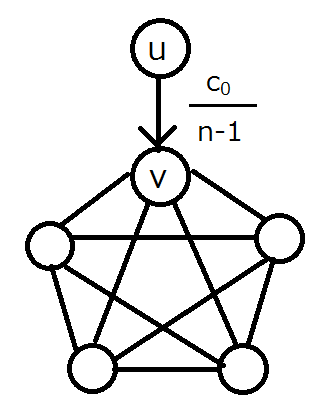
図の説明
-
クリーク内の確率は全て1
-
σ(u)+1+c0
-
Θ(n)回標本しないと(u,v)が成功しない
-
のでクリーク内も活性化しない
-
σ(v)=n-1
-
両方鑑みるとn^2
-
逆に言うと
-
標本沢山…シミュレート速い
-
標本少数…シミュレート遅い
-
シミュレート数を増やしながら確認するのが良さそう
倹約影響推定
-
$$ \sigma(S) = \mathbf{E}[i] = \sum_{1 \leq t \leq n} \Pr[I>t] $$
-
RIemann和で近似
-
$$ \pi = \sum_{t \in \{1, 1+\epsilon, (1+\epsilon)^2, \ldots, n\}} \frac{\epsilon}{1+\epsilon} t \Pr[I>t] $$
-
$$ \sigma(S) \leq \pi \leq (1+\epsilon) \sigma(S) $$
-
[I>t]を個々に考えると,シミュレーション完遂前に終えられる
倹約標本
-
$$ \pi_t = \Pr[I>t] $$
-
標本数はどれくらい?
-
t小かつπ大→I>tになりやすいので標本数少なそう
-
π小かつt大→I>tが置きないので標本数めっちゃいる
-
$$ \pi_t(L): $$ L標本時のI>tの割合
-
補題1
-
任意の$$ t>0, \tau \geq \pi, L \geq \frac{8 t \log^3 n}{\tau \epsilon^2} $$について
-
$$ \Pr[|\pi_t(L) - \pi_t| > \frac{\epsilon \tau}{t \log_{1+\epsilon}n}] \leq \frac{1}{n^2} $$
-
系2
-
w.h.p. $$ \left| \sum_{t} \frac{\epsilon}{1+\epsilon} t \pi_t(L) - \pi \right| \leq \epsilon \tau $$
アルゴリズム
-
τ←σ(S)の推定値
-
τ∈{n, n/(1+ε), n/(1+ε)^2, …, |S|}
-
VerifyGuess σ(S)~τか検証
-
$$ L=\frac{8t \log^3 n}{\tau \epsilon^2} $$に従って系2の式で推定,合ってそうなら return TRUE
-
定理3
-
σ(S)の(1+8ε)近似値を返す
-
ただし,ε<1/4
-
命題4
-
計算時間(見る影響範囲)は$$ \frac{8 (1+\epsilon) n \log^5 n}{\epsilon^2} $$ w.h.p.
分散計算
-
標本の並列化
-
VerifyGuessでのL標本
-
InfEstでVerifyGuessをlog_{1+ε}n回呼んでるそれ自体も
-
やること:以下を$$ \mathcal{O}(n \log^5 n \epsilon^{-2}) $$並列
MapReduce上の標本
-
SampleOracle: |R(S)|≧tになるランダムグラフの割合を返す
-
基本は普通のMapReduceらしい…
拡散の計算量
-
link-serverモデル
-
定理(概要)
-
1±ε誤差を確率1-δで推定するには,Ω((1-2δ)√n)クエリ必要
実験
-
設定
-
辺確率: [0,1], {0.1, 0.01}, 1/d_v
-
実グラフ: |E|<3M
-
人工グラフ: Small-world, Barabási-Albert, Kronecker, Configuration
-
環境: メモリ128GB,Python
-
比較
-
実行時間
-
近似
-
εが小さいほうが近似比良い(図が微妙)
-
真値はMC基準
-
ヒューリスティクス
まとめ
-
実験ってMapReduceじゃないの?
-
データがさすがに小さい
-
at scaleとは何なんだ…
-
これで自分のが優位とはいえないと思うんだが
KDD MapReduce 並列分散 情報拡散 独立カスケード
2015/08/19 17:17
最終更新:2015年08月19日 17:22